
糖尿病視網膜病變分析
公司代號:ZT8
實習單位:元智大學
指導老師:黃正達
姓名:張毓芷
學號:1101734
多媒體安全與影像處理實驗室包含多種領域可以學習,例如:醫學影像應用、機器學習等等。指導教授沒有強制規定研究地點,而每周會固定時間與教授進行開會與說明進度,如果遇到問題時,會再另外約時間討論,因此每周都要自己安排時間做研究,培養自學的好習慣。
02 工作詳述
訓練糖尿病視網膜病變模型,設計一套方便使用者分辦糖尿病視網膜病變之系統,將糖尿病視網膜病變程度,透過影像辨識進行分析,自動標示出該糖尿病視網膜病變之嚴重層級,並將結果透過使用者介面呈現。
01 工作環境介紹
03 工作當中扮演的角色
在工作當中,我擔任著認真討論的專題生這個角色。這個角色要求我在每一個項目和會議中都保持高度的專注和積極參與,確保我的 研究方向和進度是正確的,包括查閱相關的文獻資料、整理自己的思 路和觀點,並準備好可能會遇到的問題。我的角色不僅是參與討論和 研究,更重要的是在這個過程中不斷學習和成長。
研究動機
糖尿病視網膜病變(DR)是糖尿病引起的主要致盲原因,隨著糖尿病和老齡化人口增長,DR 患病率上升,早期無症狀常延誤診斷。臨床診斷依賴眼科醫師分析眼底影像,但受限於時間與資源。為提升效率,基於人工智慧和深度學習的自動化方法,特別是卷積神經網絡(CNN),顯著優於傳統方法。將 DR 視為迴歸問題並採用精細分級(如 ICDR),可提高病變評估精度及模型泛化能力,提升臨床應用價值。
研究方法
一、資料集
本專題基於 APTOS 2019 失明檢測 Kaggle 挑戰賽提供的數據集,旨在依據專家標籤區分視網膜眼底圖像的糖尿病視網膜病變 (Diabetic Retinopathy, DR) 嚴重層級。該數據集由 亞太遠距眼科學會 (APTOS) 發佈,圖像來源於印度阿拉文眼科醫院,涵蓋來自印度農村地區的 3,662 名受試者,每張影像均由眼科專家標註,按病變嚴重程度分為五個等級,示範圖如圖一所示,資料集嚴重層級分布如圖二所示。
圖一 : 嚴重層級示範圖

圖二 : 資料集嚴重層級分布圖

二、圖像預處理
本專題參考 APTOS 2019 失明檢測挑戰賽「神經元工程師」的預處理方法,採用多種圖像增強技術(如旋轉、翻轉、裁剪、對比度調整等),以應對不同來源與場景的圖像數據變異與噪聲問題。資料預處理通過擴展訓練數據集,提高模型對不同情境的適應性與穩定性,最終增強準確性與可靠性。
1、調整大小
將原始解析度 1050×1050 的圖片縮放至 224×224 像素,以適配 CNN 結構設計,確保特徵映射維度一致,增強特徵提取能力。
2、隨機翻轉
以 50% 機率進行水平翻轉,模擬影像方向變化,提升模型泛化能力並減少過擬合。
3、正規化
基於 ImageNet 通道平均值 [0.485, 0.456, 0.406] 和標準差 [0.229, 0.224, 0.225] 對像素值正規化,使數據分佈與預訓練模型一致,增強遷移學習效果。

三、建立模型
(一) 深度學習模型
卷積神經網絡(CNN)是一種在影像識別與特徵提取方面表現卓越的深度學習模型,廣泛應用於醫學影像分析。其典型架構包括以下部分:
-
輸入層:接收標準化和尺寸調整後的影像(如視網膜眼底影像),轉化為數值矩陣作為模型處理起點。
-
卷積層:使用濾波器(如 3×3 或 5×5)提取局部特徵(如邊緣、紋理),生成特徵圖,保留辨識信息。
-
池化層:通過最大池化或平均池化降低特徵圖維度,減少計算量並保留關鍵特徵。
-
全連接層:將特徵展平為向量,與神經元連結,完成高維特徵映射與分類決策。
-
輸出層:利用 Softmax 函數生成疾病分類的概率分佈,實現正常影像與疾病類別的分類。

(二)模型訓練
本專題採用 ResNet-101 作為核心架構,利用其深層網絡與殘差學習機制高效提取糖尿病視網膜病變(DR)的複雜病理特徵,提升分類準確性。為了進一步優化,將病變嚴重程度建模為回歸問題,精確捕捉病變等級間的連續變化,改善對病變進展的理解與診斷精確性。
研究流程圖

1
數據收集
收集APTOS 2019 失明檢測之資料集,包括糖尿病視網膜病 變患者的眼底圖與正常對照組的相關數據,以便對比分析
2
數據預處理
將數據轉換成機器學習算法能夠處理的格式,如正規化、旋轉等。
3
資料集切分
資料集按 8:2 比例切分,訓練集(80%)用於學習與調參,測試集(20%)用於性能與泛化評估,提升預測可靠性。
4
建立模型
選擇CNN將提取到的特徵作為模型的輸入,訓練模型以預測糖尿病視網膜病變的發生、發展或預後情況。
5
模型優化
根據評估結果對模型進行優化調整,包括調整模型超參數、增加訓練數據量等。
6
閥值判斷
透過測試不同閾值組合,提高少數類別預測精度最小化預測與目標分佈的差異。
四、超參數調整
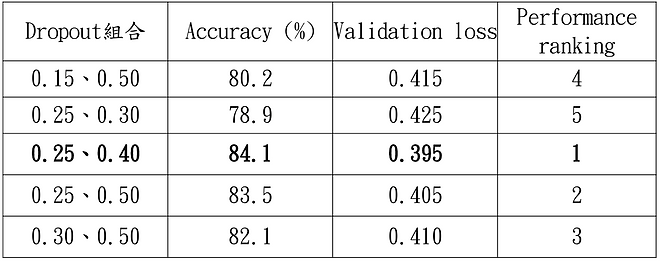
測試了五組 Dropout 超參數組合: (0.15, 0.5)、(0.25, 0.5)、(0.30, 0.5)、(0.25, 0.4)、(0.25, 0.3),分別調整輸入層與隱藏層的 Dropout 比例,並通過準確率或驗證損失值進行模型性能對比。
實驗結果顯示,適當的Dropout比例能提升模型的泛化能力與穩定性,過高或過低的比例則可能導致過擬合或欠擬合。
五、閥值調整
調整分類閾值能有效提升少數類別的預測精度,改善靈敏度、特異性等性能指標,特別適用於不平衡資料集。為此,本專題提出基於閾值調整的分布匹配方法,通過測試多組閾值,最小化預測分布與目標分布的差異,優化模型性能。
我們設定目標分布為
{0:1805, 1:370, 2:999, 3:193, 4:295}
基於訓練資料集的標籤比例,作為衡量模型預測結果與真實數據分布偏差的基準,幫助評估模型的分類效果。
1、目標設定
2、閥值調整策略
基於分類模型的概率分數,使用閾值 [t0, t1, t2, t3] 將分數映射至不同類別。設計差異指標 D 衡量預測分布與目標分布在各類別的偏差。
實驗結果表明,閾值組合 [0.79,1.71,2.51,3.1]能有效平衡分類結果分布,總差異為 188,接近目標分布。雖未完全消除偏差,但結果已在可接受範圍內,驗證了閾值調整在分布匹配中的實用性。未來可透過優化閾值或自動化方法進一步提升精度。
3、實驗調整與結果

研究成果
透過多維度指標(Accuracy、Macro avg、Weighted avg)比較 ResNet-101 原始架構與整合回歸分析策略後的性能。結果顯示,整合回歸分析後,模型在三個指標上顯著提升,表明模型在準確性、平衡性與穩定性上均有顯著改善。
結論
透過資料預處理、超參數調整及深度學習優化,建立基於卷積神經網路(CNN)與回歸分析的糖尿病視網膜病變檢測方法。專注於眼底圖像分析,並精確預測視網膜病變的嚴重層級,提升分級準確性與應用便利性。透過模型優化,顯著提升了泛化能力與穩定性,並達到最高85%的總準確率,降低驗證損失。
自我評估及心得感想
一、困難
在專題製作的過程中,我遇到了不少困難和挑戰。首先是在訂立主題與收集數據方面遇到了問題。針對糖尿病視網膜病變這一疾病, 我完全沒有任何了解,需要從零開始學習。為了能夠深入理解這個疾 病,我查閱了大量相關文章和文獻,深入研究其疾病特徵、診斷方法。 這些努力讓我更了解有關糖尿病視網膜病變的基本知識,為接下來的專題奠定了基礎。
然而,僅僅理解疾病本身還不足夠,數據處理和訓練同樣是專題 製作中的重要一環。由於程式語言並非我的強項,我面臨著極大的挑 戰。為此,我花費了大量時間學習Python程式語言,從基礎語法到應用,一步一步地增加自己的邏輯與程式能力。在這個過程中,我經歷了許多次的嘗試與錯誤,每一次的失敗都促使我更加深入地學習和思考。學習過程中不僅培養了我的耐心和抗壓性,也讓我逐步提升了自己的程式能力。每當我成功解決了一個程式錯誤時,我感受到了一 種強烈的成就感,這種成就感進一步激發了我對程式語言的熱忱。
此外,時間管理也是一個很大的挑戰。專題製作需要投入大量的時間和精力,而同時我還需要兼顧學業和其他事務。這需要我具備良好的時間管理能力,合理安排每一項工作的優先級,確保能夠按時完成各項任務。